By Tuğrul Yıldırım
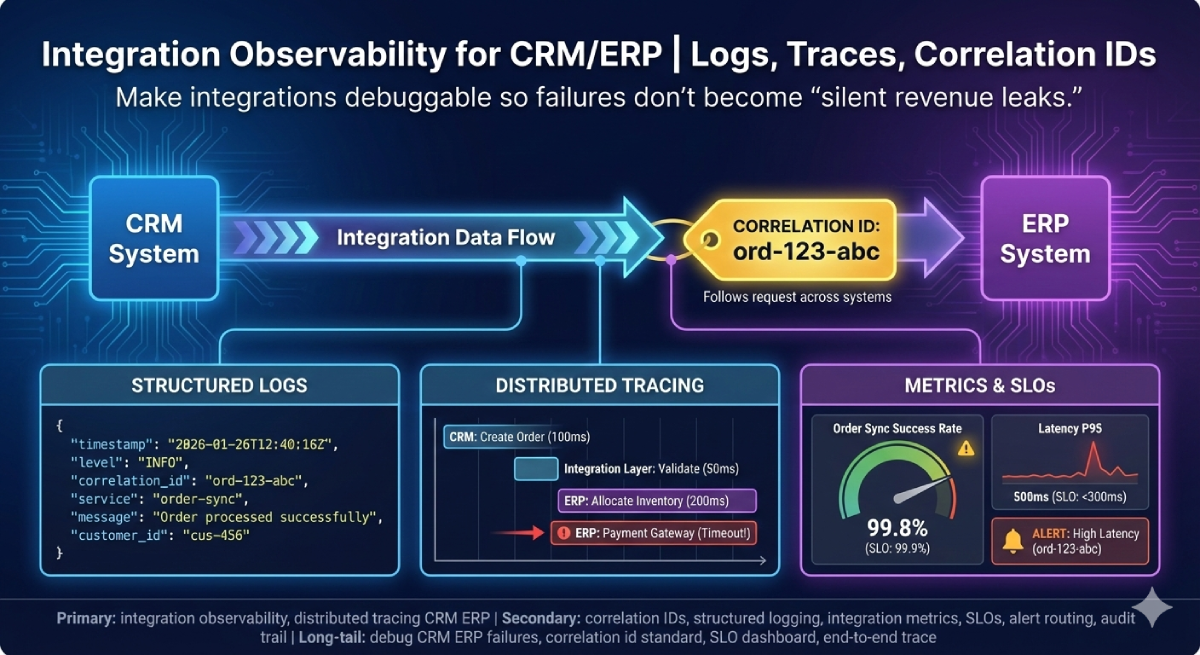
Integration Observability for CRM/ERP | Logs, Traces, Correlation IDs
Integration Observability for CRM/ERP
How to make integrations debuggable: correlation IDs, structured logs, metrics, tracing, alerting, and SLOs—so failures don’t become “silent revenue leaks.”